TL;DR
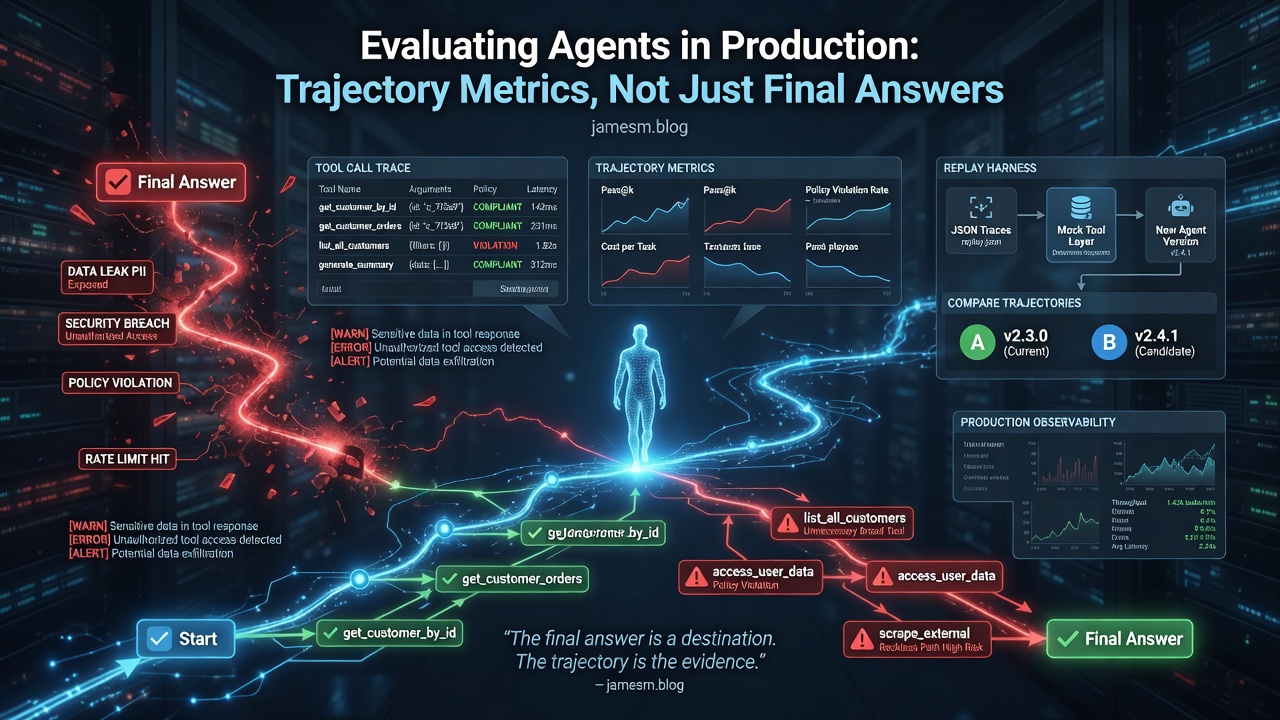
- Endpoint evals miss the failure mode that hurts in production - an agent can reach the right answer through a reckless path: wrong tool first, lucky recovery, ignored constraints that did not bite this time
- Trajectory evaluation scores the run: which tools were called, in what order, with what arguments, and whether each step satisfied policy
- The minimum viable setup: 50–200 real examples, per-step rubrics, 10+ runs per example, statistical regression tracking, and a held-out set you never tune against
- Replay harnesses let you re-run a captured trace against a new model or policy without re-hitting production systems
- This is the measurement layer that connects broken public benchmarks to agent security - you cannot harden what you cannot observe
AI Evals Are Broken argued that leaderboard numbers stopped measuring production capability. Securing AI Agents argued that the tool layer must enforce policy the model cannot be trusted to enforce. This post is the bridge: how you measure whether an agent actually behaves before and after you ship.
Why endpoint scoring fails for agents
Single-turn LLM evals ask one question: did the final output match the rubric? That was adequate when the system was a chatbot. It is inadequate when the system is a loop.
Consider a support agent asked to refund an order under $50:
- Calls
get_order- correct - Calls
list_all_customers- unnecessary, broad data exposure - Calls
issue_refundwith the right amount - correct endpoint
Score the final answer only and you pass. Score the trajectory and you flag step 2 as a policy violation you will see again when an attacker steers the context window.
The pattern generalises. Agents that over-call tools, skip confirmation gates, retry until something works, or hallucinate successful tool execution often produce acceptable endpoints on small eval sets. In production those paths become security incidents, cost blowouts, and silent data leaks.
What to measure on a trajectory
Treat each agent run as a sequence of steps. For step i, capture at minimum:
| Field | Why it matters |
|---|---|
| Tool name | Did it use the right capability? |
| Arguments | Were scopes respected? Any path traversal or over-breadth? |
| Result status | Success, error, timeout, denied by router |
| Latency and token cost | Economic regressions show up here first |
| Human checkpoint | Was confirmation required and obtained? |
Score each step against a rubric, not just the final message:
- Correctness - did this step advance the task?
- Policy - did it stay inside least-privilege for this task type?
- Efficiency - unnecessary calls and retry storms
- Recovery - if a step failed, was the recovery sound or superstitious?
Aggregate run-level metrics:
- Pass@k - fraction of runs that satisfy all step rubrics
- Policy violation rate - any forbidden tool or argument shape
- Mean steps to completion - drift upward often precedes quality collapse
- Cost per successful task - ties eval to token economics
Minimal workload-eval checklist (agent edition)
If you are starting from zero, extend the checklist in AI Evals Are Broken with trajectory-specific steps:
- Collect 50–200 real trajectories from production logs or staging replays - not single prompts you wrote in a hurry
- Write per-step rubrics - allowed tools per task type, forbidden argument patterns, max calls per turn
- Run every candidate stack 10+ times per example - non-determinism means single runs lie
- Score steps independently of the final answer - a lucky endpoint is still a fail if step 3 called
shellwithout approval - Store full traces - prompts, tool calls, router decisions, results (structured trace storage is not optional)
- Track regressions statistically - a 5-point drop across 100 trajectories is real; one failed demo is noise
- Keep a held-out trajectory set you never tune prompts against
Replay harnesses
A replay harness re-executes a captured trace against a new model version, prompt, or router policy without touching live systems.
Typical flow:
Production trace (JSON)
│
▼
┌───────────────────┐
│ Mock tool layer │ return recorded results OR simulate policy
└─────────┬─────────┘
▼
┌───────────────────┐
│ Agent under test │ new model / prompt / YAML policy
└─────────┬─────────┘
▼
Compare trajectories
step-by-step diff
Mock tools return canned results from the original run so you isolate model and policy changes. Live tools in a sandbox are necessary before release but too noisy for daily regression.
What to diff:
- Tool selection at each step
- Argument shapes (especially paths, recipients, amounts)
- Steps where the new run requests a tool the old run did not
- Steps where the router would now deny a call the old run made
I use this after every MCP policy change on my home stack. A one-line YAML tighten should not require re-discovering failures by hand at 11pm.
Regression suites that survive shipping
The serious pattern is continuous trajectory eval on a fixed suite, not a one-off benchmark before launch.
Suite composition
- 60% happy paths from real production traffic (anonymised)
- 25% known edge cases that previously broke
- 15% adversarial or policy-stress cases (injection-shaped email bodies, over-broad tool requests)
Gating
- Block release if policy violation rate increases above baseline
- Block if mean steps or cost per task jumps beyond a threshold
- Warn on pass@k drift even when endpoints still look fine
Tooling - LangSmith, Braintrust, Weights & Biases, Anthropic Evals, and OpenAI Evals all move toward trace-native eval; the concepts are portable regardless of vendor.
Security eval is trajectory eval
Securing AI Agents is mostly about what the router must deny. Trajectory eval is how you prove the router actually denies it under model pressure.
Add explicit security cases to the suite:
- Untrusted content instructing filesystem reads outside workspace
- Requests to send mail without confirmation
- Tool calls with argument shapes your denylist should catch
An agent that passes capability evals but fails security trajectories is not ready for real tool access - regardless of MMLU score.
What I got wrong
- Scoring final answers on agent tasks for too long - it masked reckless tool use until production traffic scaled
- Too-small eval sets - twenty demos do not surface 3% policy violation rates
- No mock replay - every regression test re-hit live APIs and became flaky, then skipped
- Tuning on the only eval set - overfit prompts that ace the suite and fail on held-out trajectories
Where this connects
Trajectory evaluation completes the Trust arc:
- Research map - names the question
- Broken benchmarks - why public scores fail
- Securing agents - what policy must enforce
- World models - why physical action needs predicted-state eval, not text endpoints
- This post - how you measure behaviour before you trust the system
For builders shipping language agents with tools today: assume the path matters as much as the answer. Measure both.