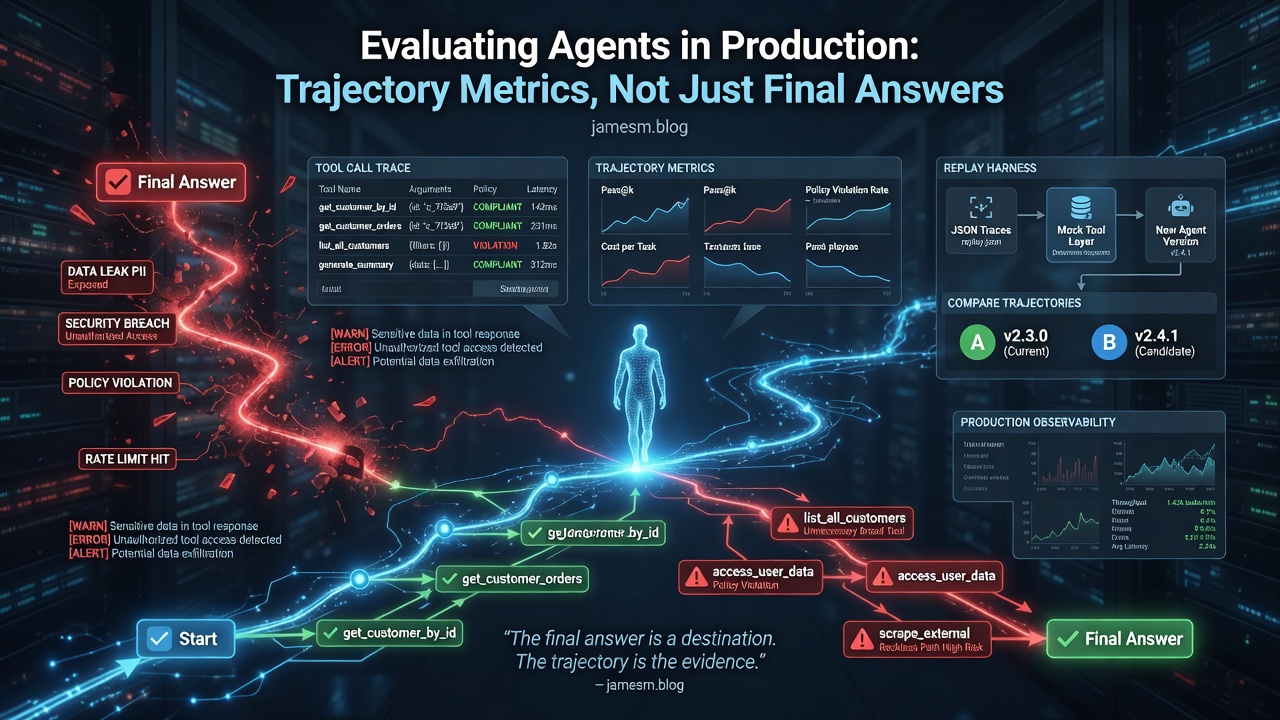
Evaluating Agents in Production: Trajectory Metrics, Not Just Final Answers
TL;DR Endpoint evals miss the failure mode that hurts in production - an agent can reach the right answer through a reckless path: wrong tool first, lucky recovery, ignored constraints that did not bite this time Trajectory evaluation scores the run: which tools were called, in what order, with what arguments, and whether each step satisfied policy The minimum viable setup: 50–200 real examples, per-step rubrics, 10+ runs per example, statistical regression tracking, and a held-out set you never tune against Replay harnesses let you re-run a captured trace against a new model or policy without re-hitting production systems This is the measurement layer that connects broken public benchmarks to agent security - you cannot harden what you cannot observe AI Evals Are Broken argued that leaderboard numbers stopped measuring production capability. Securing AI Agents argued that the tool layer must enforce policy the model cannot be trusted to enforce. This post is the bridge: how you measure whether an agent actually behaves before and after you ship. ...