An AI Tooling Learning Path: Logical Phases for 2026
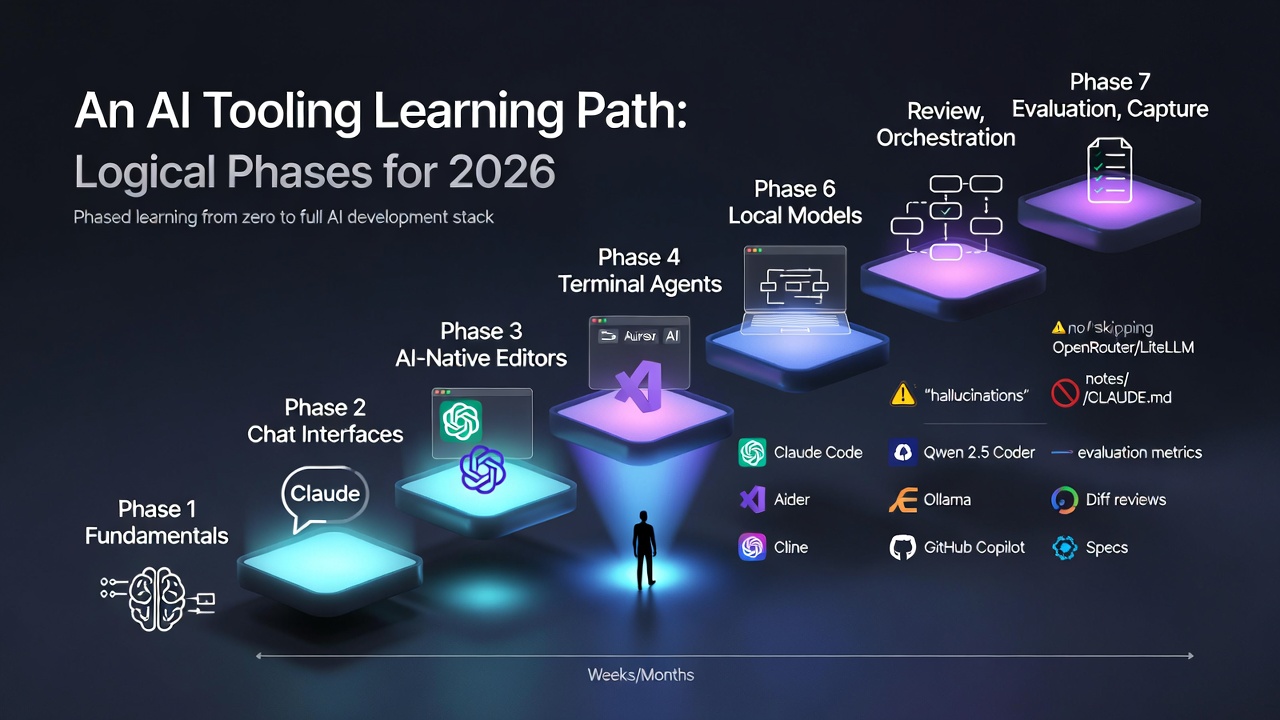
TL;DR The order you learn AI tools matters as much as which tools you learn - most people start with terminal agents or editors before they understand how models actually fail The seven-phase path runs: fundamentals, chat interfaces, AI-native editors, terminal agents, local models, orchestration, and review and evaluation Terminal agents (Claude Code, Cline, Aider) represent the biggest mindset shift - you move from driving with suggestions to specifying and letting the model execute Local models via Ollama belong in phase five, once you have felt the pain of API costs and know which tasks actually need frontier capability Review, evaluation, and capture (phase seven) is the phase most developers skip - and the one that separates AI-curious from AI-competent The hardest part of learning AI tooling in 2026 is not any single tool. It is the order you meet them in. ...




