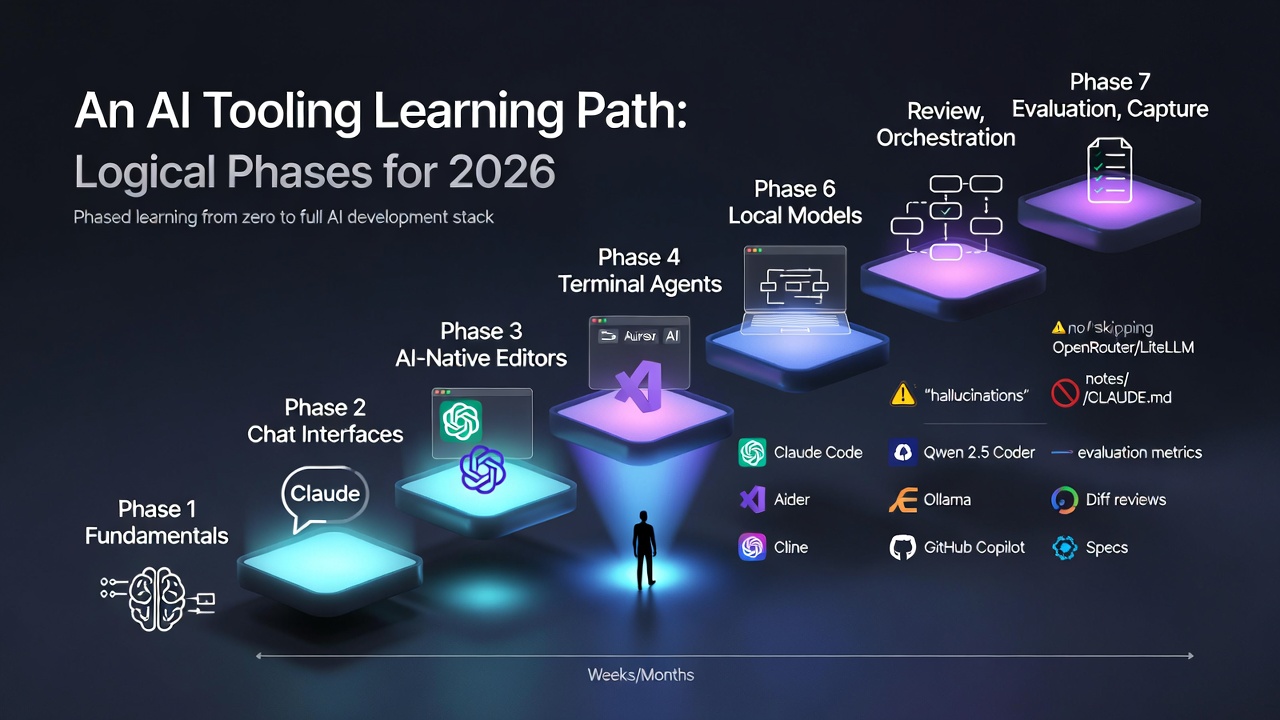
The Next Decade of AI: What Actually Happens From Here
TL;DR AI will not arrive as a single dramatic event - it will be a slow, uneven embedding of intelligence into ordinary software until it becomes invisible infrastructure, like electricity The agent layer will eat the interface: for a growing share of tasks, humans will give high-level intent to an agent that drives other software on their behalf, making the SaaS dashboard model look dated The scarce resource shifts from generating answers to judging which answer is right - hiring, education, and professional identity will all restructure around this AI splits into two permanent species: powerful, expensive frontier models in the cloud, and fast, private, cheap local models - with hybrid architectures winning in practice Reliability, not capability, becomes the dominant engineering problem as agents move from co-pilots to operators; the field must invent new testing and monitoring disciplines for non-deterministic systems Most predictions about the future of AI fall into two flavours. One camp says we are months away from machines that can do everything a human can do, and we should brace for either paradise or extinction. The other camp says the whole thing is a bubble, the models have plateaued, and in five years we will be talking about something else. ...